كيفية تشغيل Apache Spark على Kubernetes في أقل من 5 دقائق

ستقطع أدوات مثل Ilum شوطا طويلا في تبسيط عملية تثبيت Apache Spark على Kubernetes. سيأخذك هذا الدليل ، خطوة بخطوة ، إلى كيفية تشغيل Spark جيدا على مجموعة Kubernetes الخاصة بك. باستخدام Ilum ، يتم نشر مجموعات Apache Spark وإدارتها وتوسيع نطاقها بسهولة وبشكل طبيعي.
مقدمة
اليوم ، سنعرض كيفية النهوض والتشغيل باستخدام Apache Spark على K8s. هناك العديد من الطرق للقيام بذلك ، ولكن معظمها معقد ويتطلب العديد من التكوينات. سوف نستخدم إيلوم نظرا لأن ذلك سيقوم بكل إعداد نظام المجموعة نيابة عنا. في منشور المدونة التالي ، سنقارن الاستخدام مع عامل Spark.
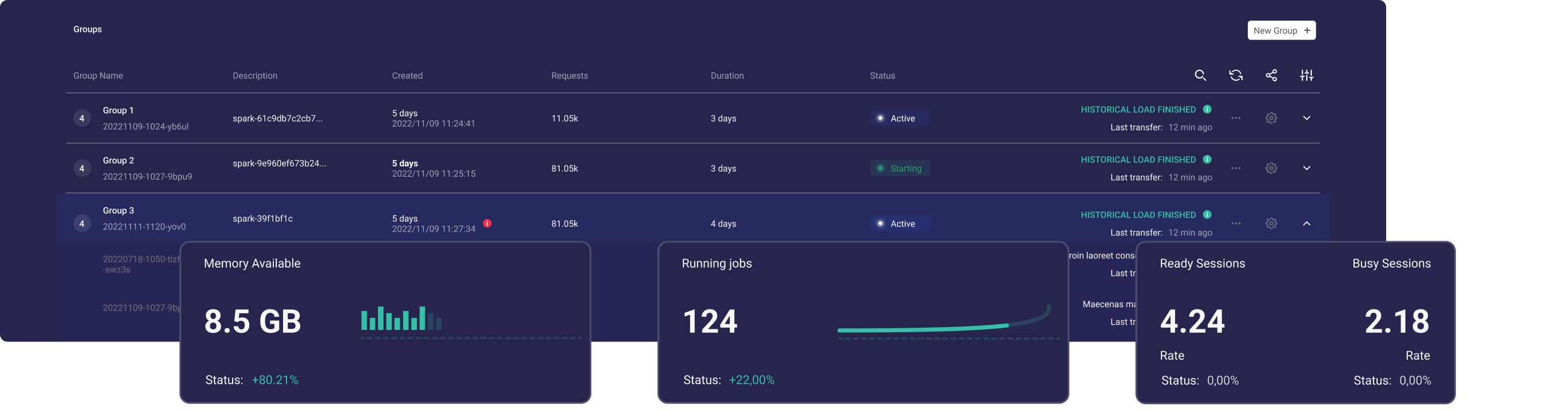
Ilum عبارة عن بحيرة بيانات مجانية ومعيارية لنشر مجموعات Apache Spark وإدارتها بسهولة. يحتوي على واجهة برمجة تطبيقات بسيطة لتحديد Spark وإدارته ، وسوف يتعامل مع جميع التبعيات. يساعد في إنشاء الشرارة المدارة الخاصة بك.
باستخدام Ilum، يمكنك نشر مجموعات Spark في دقائق والبدء على الفور في تشغيل تطبيقات Spark. يتيح لك Ilum توسيع نطاقها بسهولة وفي مجموعات Spark الخاصة بك ، وإدارة مجموعات Spark متعددة من واجهة مستخدم واحدة.
مع Ilum ، يكون البدء أمرا سهلا إذا كنت جديدا نسبيا على Apache Spark على Kubernetes.
دليل خطوة بخطوة لتثبيت Apache Spark على Kubernetes
بداية سريعة
نفترض أن لديك مجموعة Kubernetes قيد التشغيل ، فقط في حالة عدم القيام بذلك ، تحقق من هذه الإرشادات لإعداد مجموعة Kubernetes على minikube. تحقق من كيفية تثبيت minikube .
إعداد مجموعة kubernetes محلية
- قم بتثبيت Minikube: قم بتنفيذ الأمر التالي لتثبيت Minikube جنبا إلى جنب مع الموارد الموصى بها. سيؤدي هذا إلى تثبيت Minikube مع 6 وحدات معالجة مركزية افتراضية وذاكرة 12288 ميجابايت بما في ذلك الوظيفة الإضافية لخادم المقاييس الضرورية للمراقبة.
بدء minikube - وحدة المعالجة المركزية 6 - الذاكرة 12288 - الإضافات المقاييس الخادم بمجرد أن يكون لديك مجموعة Kubernetes قيد التشغيل، لا يبعد سوى بضعة أوامر لتثبيت Ilum:
قم بتثبيت Spark على Kubernetes باستخدام Ilum
- جمع مستودع Ilum Helm
خوذة الريبو إضافة ILUM https://charts.ilum.cloud - تثبيت Ilum في نظام المجموعة الخاص بك
Here we have a few options.
a) The recommended one is to start with a few additional modules turned on (Data Lineage, SQL, Data Catalog).
helm install ilum ilum/ilum \
--set ilum-hive-metastore.enabled=true \
--set ilum-core.metastore.enabled=true \
--set ilum-sql.enabled=true \
--set ilum-core.sql.enabled=true \
--set global.lineage.enabled=trueb) you can also start with the most basic option which has only Spark and Jupyter notebooks.
Helm تثبيت ilum ilum / ilum c) there is also an option to use ilum's module selection tool هنا .
minikube ssh docker pull ilum/core:6.6.0
يجب أن يستغرق هذا الإعداد حوالي دقيقتين. سيتم نشر Ilum في مجموعة Kubernetes الخاصة بك، وإعدادها للتعامل مع مهام Spark.
بمجرد تثبيت Ilum ، يمكنك الوصول إلى واجهة المستخدم باستخدام port-forward و localhost: 9777.
- إعادة توجيه المنفذ للوصول إلى واجهة المستخدم: استخدم إعادة توجيه منفذ Kubernetes للوصول إلى واجهة مستخدم Ilum.
المنفذ إلى الأمام SVC / ILUM-UI 9777: 9777 استخدام المسؤول / المسؤول كبيانات اعتماد افتراضية. يمكنك تغييرها أثناء عملية النشر .
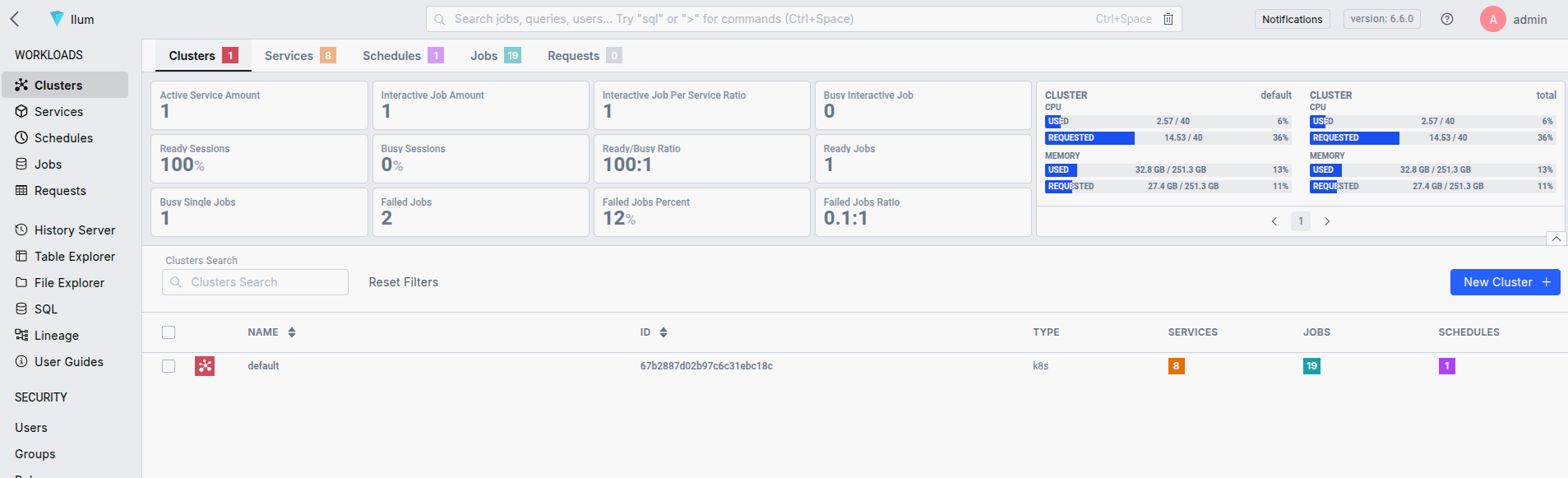
هذا كل شيء، تم الآن تكوين مجموعة kubernetes الخاصة بك للتعامل مع مهام الشرارة. يوفر Ilum واجهة برمجة تطبيقات وواجهة مستخدم بسيطة تسهل إرسال طلبات Spark. يمكنك أيضا استخدام القديم الجيد إرسال شرارة .
نشر تطبيق spark على kubernetes
لنبدأ الآن مهمة شرارة بسيطة. سنستخدم مثال "SparkPi" من Spark توثيق . يمكنك استخدام ملف jar من هذا رابط .
ILUM إضافة وظيفة شرارة
سيقوم Ilum بإنشاء جراب Kubernetes لبرنامج تشغيل Spark ، ويستخدم صورة عامل الإرساء الإصدار 3.x. يمكنك التحكم في عدد جراب منفذ الشرارة عن طريق تحجيمها إلى عقد متعددة. هذه هي أبسط طريقة لتقديم طلبات الشرارة إلى K8s.

يعد تشغيل Spark على Kubernetes أمرا سهلا حقا وخاليا من الاحتكاك مع Ilum. سيقوم بتكوين نظام المجموعة بأكمله ويقدم لك واجهة حيث يمكنك إدارة مجموعة Spark الخاصة بك ومراقبتها. نعتقد أن تطبيقات spark على Kubernetes هي مستقبل البيانات الضخمة. باستخدام Kubernetes ، ستتمكن تطبيقات Spark من التعامل مع كميات هائلة من البيانات بشكل أكثر موثوقية ، وبالتالي إعطاء رؤى دقيقة والقدرة على اتخاذ القرارات باستخدام البيانات الضخمة.
تقديم طلب Spark إلى Kubernetes (النمط القديم)
يتضمن إرسال وظيفة Spark إلى مجموعة Kubernetes استخدام شرارة تقديم البرنامج النصي مع التكوينات الخاصة ب Kubernetes. إليك دليل تفصيلي:
الخطوات :
-
قم بإعداد تطبيق Spark قم بتجميع تطبيق Spark الخاص بك في ملف JAR (ل Scala / Java) أو برنامج نصي Python.:
-
استخدام
شرارة تقديمللنشر تنفيذ العلامة:شرارة تقديممع الخيارات الخاصة ب Kubernetes:./bin/spark-submit \ --master k8s://https<k8s-apiserver-host>://:<k8s-apiserver-port> \ --نشر نظام المجموعة \ --اسم شرارة التطبيق \ --class org.apache.spark.examples.SparkPi \ --conf spark.executor.instances=3 \ --conf spark.kubernetes.container.image=<your-spark-image> \ local:///path/to/your-app.jarاستبدل:
<k8s-apiserver-host>مضيف خادم واجهة برمجة تطبيقات Kubernetes.:<k8s-apiserver-port>منفذ خادم واجهة برمجة تطبيقات Kubernetes.:<your-spark-image>صورة Docker التي تحتوي على Spark.:local:///path/to/your-app.jarالمسار إلى JAR للتطبيق الخاص بك داخل صورة Docker.:
التكوينات الرئيسية :
--أحسنيحدد عنوان URL لواجهة برمجة تطبيقات Kubernetes.:--وضع النشرالضبط علىعنقودلتشغيل برنامج التشغيل داخل مجموعة Kubernetes.--اسمتسمي تطبيق Spark الخاص بك.:--فصلالفئة الرئيسية لتطبيقك.:--conf spark.executor.instancesعدد الكبسولات المنفذة.:- conf spark.kubernetes.container.imageصورة Docker لكبسولات Spark.:
لمزيد من التفاصيل، يرجى الرجوع إلى وثائق Apache Spark حول التشغيل على Kubernetes .
2. إنشاء صورة Docker مخصصة ل Spark
يتيح لك إنشاء صورة Docker مخصصة حزم تطبيق Spark الخاص بك وتبعياته، مما يضمن الاتساق عبر البيئات.
الخطوات :
-
إنشاء Dockerfile تحديد البيئة والتبعيات.:
# استخدم صورة قاعدة Spark الرسمية من شرارة:3.5.3 # تعيين متغيرات البيئة ENV SPARK_HOME = / opt / شرارة مسار البيئة = $PATH: $SPARK_HOME / بن # انسخ تطبيق JAR الخاص بك في الصورة نسخ your-app.jar $SPARK_HOME/examples/jars/ # قم بتعيين نقطة الدخول لتشغيل التطبيق الخاص بك نقطة الدخول ["spark-submit", "--class", "org.apache.spark.examples.SparkPi", "--master", "local[4]", "/opt/spark/examples/jars/your-app.jar"]في ملف Docker هذا:
من شرارة:3.5.3يستخدم صورة Spark الرسمية كقاعدة.:الحياه الفطريهلتعيين متغيرات البيئة ل Spark.:نسخيضيف تطبيق JAR الخاص بك إلى الصورة.:نقطة الدخوليحدد الأمر الافتراضي لتشغيل تطبيق Spark.:
-
بناء صورة Docker استخدم Docker لبناء صورتك.:
docker build -t your-repo / your-spark-app: latest .استبدل
الخاص بك ريبو / الخاص بك شرارة التطبيقمع مستودع Docker واسم الصورة. -
دفع الصورة إلى سجل قم بتحميل صورتك إلى سجل Docker الذي يمكن الوصول إليه بواسطة مجموعة Kubernetes.:
عامل الإرساء دفع الخاص بك ريبو / شرارة التطبيق الخاص بك: الأحدث
أثناء الاستخدام شرارة تقديم هي طريقة شائعة لنشر تطبيقات Spark ، وقد لا تكون النهج الأكثر كفاءة لبيئات الإنتاج. يمكن أن تؤدي عمليات الإرسال اليدوية إلى عدم الاتساق ويمثل صعوبة في دمجها في مهام سير العمل الآلية. لتعزيز الكفاءة وقابلية الصيانة ، يوصى بالاستفادة من واجهة برمجة تطبيقات REST الخاصة ب Ilum.
أتمتة عمليات نشر Spark باستخدام واجهة برمجة تطبيقات REST الخاصة ب Ilum
تقدم Ilum واجهة برمجة تطبيقات RESTful قوية تتيح التفاعل السلس مع مجموعات Spark. تسهل واجهة برمجة التطبيقات هذه أتمتة عمليات إرسال الوظائف والمراقبة والإدارة ، مما يجعلها خيارا مثاليا لمسارات التكامل المستمر / النشر المستمر (CI / CD).
فوائد استخدام واجهة برمجة تطبيقات REST الخاصة ب Ilum:
- اتمته دمج عمليات إرسال وظائف Spark في مسارات CI/CD، مما يقلل من التدخل اليدوي والأخطاء المحتملة.:
- الاتساق ضمان عمليات نشر موحدة عبر بيئات مختلفة.:
- قابلية التوسع إدارة مجموعات Spark المتعددة والوظائف بسهولة برمجيا.:
مثال: إرسال مهمة Spark عبر واجهة برمجة تطبيقات REST الخاصة ب Ilum
لإرسال وظيفة Spark باستخدام واجهة برمجة تطبيقات REST الخاصة ب Ilum ، يمكنك تقديم طلب HTTP POST مع المعلمات الضرورية. فيما يلي مثال مبسط باستخدام حليقه :
curl -X POST https:// <ilum-server>/ api / v1 / job / submit \
-H "نوع المحتوى: متعدد الأجزاء / بيانات النموذج" \
-F "الاسم = مثال الوظيفة" \
-F "clusterName = default" \
-F "jobClass=org.apache.spark.examples.SparkPi" \
-F "الجرار = @ / المسار / إلى / your-app.jar" \
-F "jobConfig = spark.executor.instances = 3 ؛ spark.executor.memory=4 جي " في هذا الأمر:
اسميحدد اسم الوظيفة.:clusterNameيشير إلى المجموعة المستهدفة.:فئة الوظيفةيحدد الفئة الرئيسية لتطبيق Spark الخاص بك.:الجرارتحميل ملف JAR للتطبيق الخاص بك.:jobConfigلتعيين تكوينات Spark، مثل عدد المنفذين وتخصيص الذاكرة.:
للحصول على معلومات مفصلة حول نقاط نهاية واجهة برمجة التطبيقات والمعلمات، يرجى الرجوع إلى وثائق واجهة برمجة تطبيقات Ilum .
تعزيز الكفاءة من خلال وظائف Spark التفاعلية
بالإضافة إلى أتمتة عمليات إرسال الوظائف، يمكن أن يؤدي تحويل وظائف Spark إلى خدمات مصغرة تفاعلية إلى تحسين استخدام الموارد وأوقات الاستجابة بشكل كبير. يدعم Ilum إنشاء جلسات Spark التفاعلية طويلة الأمد التي يمكنها معالجة البيانات في الوقت الفعلي دون النفقات العامة لتهيئة سياق Spark جديد لكل طلب.
مزايا وظائف الشرارة التفاعلية:
- تقليل زمن الوصول يلغي الحاجة إلى بدء سياق Spark جديد لكل وظيفة، مما يؤدي إلى تنفيذ أسرع.:
- تحسين الموارد يحافظ على سياق Spark المستمر، مما يسمح بإدارة الموارد بكفاءة.:
- قابلية التوسع يعالج طلبات متعددة بشكل متزامن خلال نفس جلسة Spark.:
لتنفيذ مهمة Spark التفاعلية مع Ilum ، يمكنك تحديد تطبيق Spark الذي يستمع إلى البيانات الواردة ويعالجها في الوقت الفعلي. هذا النهج مفيد بشكل خاص للتطبيقات التي تتطلب معالجة البيانات والاستجابة الفورية.
للحصول على دليل شامل حول إعداد وظائف Spark التفاعلية وتحسين مجموعة Spark الخاصة بك ، راجع منشور مدونة Ilum: كيفية تحسين مجموعة Spark الخاصة بك باستخدام وظائف Spark التفاعلية .
من خلال دمج واجهة برمجة تطبيقات REST الخاصة ب Ilum واعتماد وظائف Spark التفاعلية ، يمكنك تبسيط سير عمل Spark ، وتحسين الأتمتة ، وتحقيق بيئة معالجة بيانات أكثر كفاءة وقابلية للتطوير.
مزايا استخدام Ilum لتشغيل Spark على Kubernetes
تم تجهيز Ilum بواجهة مستخدم سهلة الاستخدام وواجهة برمجة تطبيقات مرنة لتوسيع نطاق مجموعات Spark والتعامل معها ، وتكوين تطبيقين من Spark من واجهة واحدة. فيما يلي بعض الميزات الرائعة في هذا الصدد:
- سهولة الاستعمال يبسط Ilum تكوين Spark وإدارته على Kubernetes باستخدام واجهة مستخدم Spark سهلة الاستخدام ، مما يلغي عمليات الإعداد المعقدة.:
- النشر السريع: قم بإعداد مجموعات Spark ونشرها وتوسيع نطاقها في دقائق لتسريع الوقت اللازم لتنفيذ التطبيقات واختبارها على الفور.
- قابلية التوسع: باستخدام واجهة برمجة تطبيقات Kubernetes، يمكنك بسهولة توسيع نطاق مجموعات Spark لأعلى أو لأسفل لتلبية احتياجات معالجة البيانات الخاصة بك، مما يضمن الاستخدام الأمثل للموارد.
- نمطيه يأتي Ilum مزودا بإطار عمل معياري يسمح للمستخدمين باختيار مكونات مختلفة ودمجها مثل Spark History Server و Apache Jupyter و Minio وغير ذلك الكثير.:
الهجرة من غزل أباتشي هادووب
الآن بعد أن أصبح Apache Hadoop Yarn في حالة ركود عميق ، تتطلع المزيد والمزيد من المنظمات إلى الهجرة من Yarn إلى Kubernetes. يعزى هذا إلى عدة أسباب ، ولكن الأكثر شيوعا هو أن Kubernetes يوفر نظاما أساسيا أكثر مرونة ومرونة في مسائل إدارة أعباء عمل البيانات الضخمة.
بشكل عام ، من الصعب إجراء ترحيل النظام الأساسي لمنصة معالجة البيانات من Apache Hadoop Yarn إلى أي نظام آخر. هناك العديد من العوامل التي يجب مراعاتها عند إجراء مثل هذا التبديل - توافق البيانات والسرعة وتكلفة المعالجة. ومع ذلك ، سيأتي الأمر بسلاسة ونجاح إذا تم التخطيط للإجراء وتنفيذه بشكل جيد.
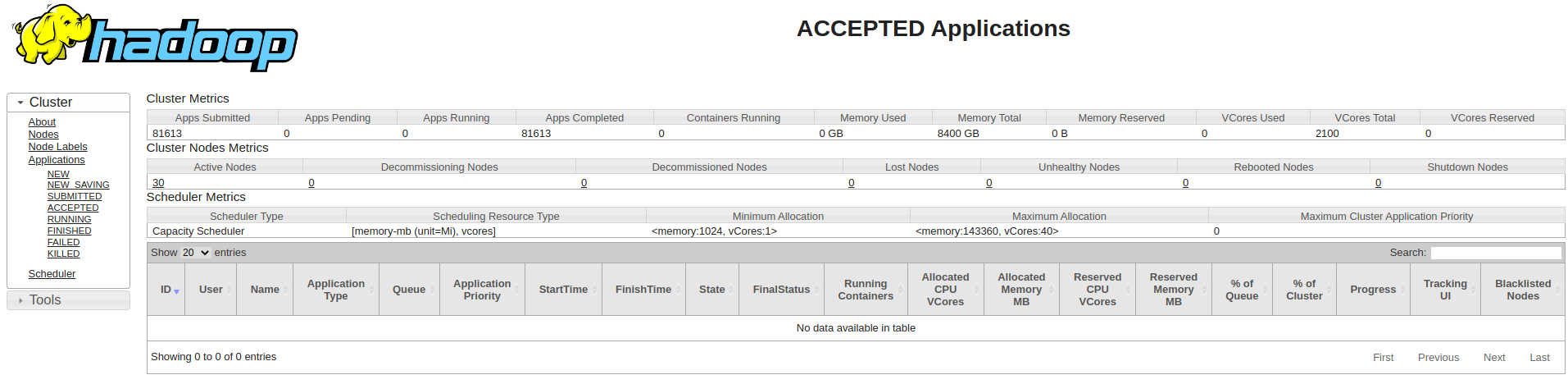
يعد Kubernetes مناسبا بشكل طبيعي عندما يتعلق الأمر بأعباء عمل البيانات الضخمة نظرا لقدرته المتأصلة على القدرة على التوسع أفقيا. ولكن ، مع Hadoop Yarn ، أنت مقيد بعدد العقد في مجموعتك. يمكنك زيادة عدد العقد داخل مجموعة Kubernetes وتقليلها عند الطلب.
كما يسمح بالميزات غير المتوفرة في Yarn ، على سبيل المثال: الشفاء الذاتي والقياس الأفقي.
حان الوقت للتبديل إلى Kubernetes؟
مع استمرار تطور عالم البيانات الضخمة ، تتطور الأدوات والتقنيات المستخدمة لإدارتها. لسنوات ، كان Apache Hadoop YARN هو المعيار الفعلي لإدارة الموارد في بيئات البيانات الضخمة. ولكن مع ظهور تقنيات الحاويات والتنسيق مثل Kubernetes ، هل حان الوقت لإجراء التبديل؟
اكتسبت Kubernetes شعبية كمنصة تنسيق للحاويات ، ولسبب وجيه. إنه مرن وقابل للتطوير وسهل الاستخدام نسبيا. إذا كنت لا تزال تستخدم البنية الأساسية التقليدية المستندة إلى الجهاز الظاهري، فقد يكون الوقت قد حان الآن للتبديل إلى Kubernetes.
إذا كنت تعمل مع حاويات ، فعليك بالتأكيد الاهتمام ب Kubernetes. يمكن أن يساعدك في إدارة الحاويات الخاصة بك ونشرها بشكل أكثر فاعلية ، وهو مفيد بشكل خاص إذا كنت تعمل مع الكثير من الحاويات أو إذا كنت تنشر حاوياتك على نظام أساسي سحابي.
يعد Kubernetes أيضا خيارا رائعا إذا كنت تبحث عن أداة تنسيق مدعومة من شركة تقنية كبرى. تستخدم Google Kubernetes لسنوات لإدارة تطبيقاتها المعبأة في حاويات ، وقد استثمرت الكثير من الوقت والموارد في جعلها أداة رائعة.
لا يوجد فائز واضح في مناظرة YARN مقابل Kubernetes. يعتمد الحل الأفضل لمؤسستك على احتياجاتك الخاصة وحالات الاستخدام. إذا كنت تبحث عن حل إدارة موارد أكثر مرونة وقابلية للتطوير ، فإن Kubernetes يستحق التفكير. إذا كنت بحاجة إلى دعم أفضل للتطبيقات القديمة ، فقد يكون YARN خيارا أفضل.
أيا كانت المنصة التي تختارها ، يمكن أن تساعدك Ilum في تحقيق أقصى استفادة منها. تم تصميم منصتنا للعمل مع كل من YARN و Kubernetes ، ويمكن لفريق الخبراء لدينا مساعدتك في اختيار وتنفيذ الحل المناسب لمؤسستك.
مجموعة Spark المدارة
مجموعة Spark المدارة هي حل قائم على السحابة يجعل من السهل توفير مجموعات Spark وإدارتها. يوفر واجهة مستندة إلى الويب لإنشاء مجموعات Spark وإدارتها، بالإضافة إلى مجموعة من واجهات برمجة التطبيقات لأتمتة مهام إدارة نظام المجموعة. غالبا ما يتم استخدام مجموعات Spark المدارة من قبل علماء البيانات والمطورين الذين يرغبون في توفير مجموعات Spark وإدارتها بسرعة دون الحاجة إلى القلق بشأن البنية التحتية الأساسية.
يوفر Ilum القدرة على إنشاء وإدارة مجموعة الشرارة الخاصة بك ، والتي يمكن تشغيلها في أي بيئة ، بما في ذلك السحابة أو المحلية أو مزيج من الاثنين معا.

إيجابيات Apache Spark على Kubernetes
كان هناك بعض الجدل حول ما إذا كان يجب تشغيل Apache Spark على Kubernetes.
يجادل بعض الأشخاص بأن Kubernetes معقد للغاية وأن Spark يجب أن يستمر في العمل على مدير نظام المجموعة المخصص الخاص به أو البقاء في السحابة. يجادل آخرون بأن Kubernetes هو مستقبل معالجة البيانات الضخمة وأن Spark يجب أن تتبناها.
نحن في المعسكر الأخير. نعتقد أن Kubernetes هو مستقبل معالجة البيانات الضخمة وأن Apache Spark يجب أن يعمل على Kubernetes.
أكبر فائدة لاستخدام Spark على Kubernetes هي أنه يسمح بتوسيع نطاق تطبيقات Spark بشكل أسهل. وذلك لأن Kubernetes مصمم للتعامل مع عمليات نشر أعداد كبيرة من الحاويات المتزامنة. لذلك، إذا كان لديك تطبيق Spark يحتاج إلى معالجة الكثير من البيانات، فيمكنك ببساطة نشر المزيد من الحاويات إلى مجموعة Kubernetes لمعالجة البيانات بالتوازي. هذا أسهل بكثير من إعداد مجموعة Spark جديدة على EMR في كل مرة تحتاج فيها إلى توسيع نطاق المعالجة. يمكنك تشغيله على أي نظام أساسي سحابي (AWS و Google Cloud و Azure وما إلى ذلك) أو محليا. هذا يعني أنه يمكنك بسهولة نقل تطبيقات Spark من بيئة إلى أخرى دون الحاجة إلى القلق بشأن تغيير مدير نظام المجموعة الخاص بك.
فائدة هائلة أخرى هي أنه يسمح بسير عمل أكثر مرونة. على سبيل المثال، إذا كنت بحاجة إلى معالجة البيانات من مصادر متعددة، فيمكنك بسهولة نشر حاويات مختلفة لكل مصدر ومعالجتها جميعا بالتوازي. هذا أسهل بكثير من محاولة إدارة سير عمل معقد على مجموعة Spark واحدة.
يحتوي Kubernetes على العديد من ميزات الأمان التي تجعله خيارا أكثر جاذبية لتشغيل تطبيقات Spark. على سبيل المثال، يدعم Kubernetes التحكم في الوصول المستند إلى الدور، والذي يسمح لك بضبط من لديه حق الوصول إلى مجموعة Spark الخاصة بك.
لذلك هناك لديك. هذه ليست سوى بعض الأسباب التي تجعلنا نعتقد أن Apache Spark يجب أن يعمل على Kubernetes. إذا لم تكن مقتنعا ، فنحن نشجعك على تجربته بنفسك. نعتقد أنك ستندهش من مدى نجاحها.
موارد إضافية
- تحقق من كيفية تثبيت Minikube
- وثائق Kubernetes
- الموقع الرسمي ل Ilum
- الوثائق الرسمية ل Ilum
- مخطط Ilum Helm
استنتاج
يبسط Ilum عملية تثبيت وإدارة Apache Spark على Kubernetes ، مما يجعله خيارا مثاليا لكل من المستخدمين المبتدئين وذوي الخبرة. باتباع هذا الدليل ، سيكون لديك مجموعة Spark وظيفية تعمل على Kubernetes في أي وقت من الأوقات.