كيفية تحسين مجموعة Spark الخاصة بك باستخدام وظائف Spark التفاعلية

في هذه المقالة سوف تتعلم:
- كيفية تقليل وقت تنفيذ مهمة الشرارة
- ما هي الوظيفة التفاعلية في إيلوم
- كيفية تشغيل وظيفة شرارة تفاعلية
- الاختلافات بين تشغيل مهمة شرارة باستخدام Ilum API و Spark API
أنواع وظائف Ilum
هناك ثلاثة أنواع من الوظائف التي يمكنك تشغيلها في Ilum: وظيفة واحدة , وظيفة تفاعلية و كود تفاعلي . في هذه المقالة ، سنركز على وظيفة تفاعلية نوع. ومع ذلك ، من المهم معرفة الاختلافات بين الأنواع الثلاثة للوظائف ، لذلك دعونا نلقي نظرة عامة سريعة على كل منها.
مع وظائف فردية ، يمكنك إرسال برامج تشبه التعليمات البرمجية. إنها تسمح لك بإرسال تطبيق Spark إلى نظام المجموعة، باستخدام تعليمات برمجية مجمعة مسبقا، دون تفاعل أثناء وقت التشغيل. في هذا الوضع ، يجب عليك إرسال جرة مجمعة إلى Ilum ، والتي تستخدم لبدء وظيفة واحدة. يمكنك إما إرسالها مباشرة ، أو يمكنك استخدام بيانات اعتماد AWS للحصول عليها من حاوية S3. مثال نموذجي لاستخدام وظيفة واحدة هو نوع من مهمة إعداد البيانات.
يوفر Ilum أيضا تبادلي وضع الكود ، مما يسمح لك بإرسال الأوامر في وقت التشغيل. هذا مفيد للمهام التي تحتاج فيها إلى التفاعل مع البيانات ، مثل تحليل البيانات الاستكشافية.
وظيفة تفاعلية
تحتوي الوظائف التفاعلية على جلسات عمل طويلة الأمد، حيث يمكنك إرسال بيانات مثيل الوظيفة ليتم تنفيذها على الفور. الميزة القاتلة لمثل هذا الوضع هي أنك لست مضطرا إلى الانتظار حتى يتم تهيئة سياق الشرارة. إذا كان المستخدمون يشيرون إلى نفس معرف الوظيفة، فسيتفاعلون مع سياق الشرارة نفسه. يقوم Ilum بتغليف منطق تطبيق Spark في وظيفة Spark طويلة الأمد والتي تكون قادرة على معالجة طلبات الحساب على الفور، دون الحاجة إلى انتظار تهيئة سياق Spark.
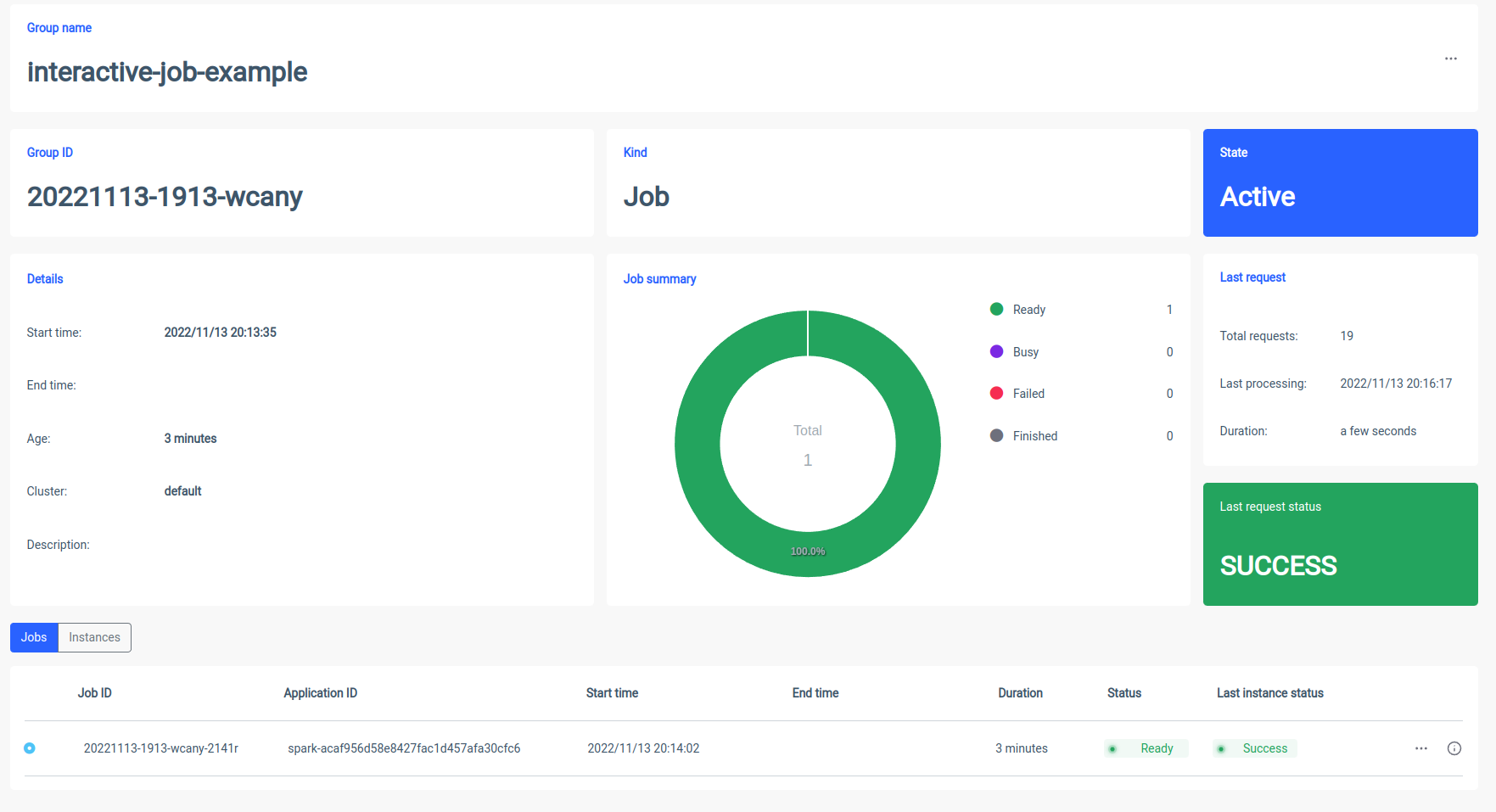
بدء وظيفة تفاعلية
دعنا نلقي نظرة على كيفية بدء جلسة Ilum التفاعلية. أول شيء يتعين علينا القيام به هو إعداد Ilum. يمكنك القيام بذلك بسهولة باستخدام minikube. يتوفر برنامج تعليمي مع تثبيت Ilum تحت هذا رابط . في الخطوة التالية ، يتعين علينا إنشاء ملف jar يحتوي على تنفيذ لواجهة وظيفة Ilum. لاستخدام واجهة برمجة تطبيقات وظائف Ilum ، يتعين علينا إضافتها إلى المشروع مع بعض مديري التبعية ، مثل Maven أو Gradle. في هذا المثال، سنستخدم بعض التعليمات البرمجية ل Scala مع Gradle لحساب PI.
المثال الكامل متاح على موقعنا جيت هب .
إذا كنت تفضل عدم إنشائه بنفسك ، فيمكنك العثور على ملف الجرة المترجم هنا .
الخطوة الأولى هي إنشاء مجلد لمشروعنا وتغيير الدليل إليه.
$ mkdir مثال على الوظيفة التفاعلية
$ cd مثال على الوظيفة التفاعلية إذا لم يكن لديك أحدث إصدار من Gradle مثبتا على جهاز الكمبيوتر الخاص بك ، فيمكنك التحقق من كيفية القيام بذلك هنا . ثم قم بتشغيل الأمر التالي في محطة طرفية من داخل دليل المشروع:
$ gradle init اختر تطبيق Scala مع Groovy بتنسيق DSL. يجب أن يبدو الإخراج كما يلي:
بدء تشغيل Gradle Daemon (ستكون الإصدارات اللاحقة أسرع)
حدد نوع المشروع المراد إنشاؤه:
1: أساسي
2: التطبيق
3: المكتبة
4: البرنامج المساعد Gradle
أدخل التحديد (الافتراضي: أساسي) [1..4] 2
حدد لغة التنفيذ:
1: C ++
2: رائع
3: جافا
4: كوتلين
5: سكالا
6: سويفت
أدخل التحديد (الافتراضي: Java) [1..6] 5
تقسيم الوظائف عبر مشاريع فرعية متعددة؟:
1: لا - مشروع تطبيق واحد فقط
2: نعم - مشاريع التطبيقات والمكتبة
أدخل التحديد (الافتراضي: لا - مشروع تطبيق واحد فقط) [1..2] 1
حدد البرنامج النصي للإنشاء DSL:
1: رائع
2: كوتلين
أدخل التحديد (الافتراضي: رائع) [1..2] 1
إنشاء بنية باستخدام واجهات برمجة التطبيقات والسلوك الجديد (قد تتغير بعض الميزات في الإصدار الثانوي التالي)؟ (الافتراضي: لا) [نعم ، لا] لا
اسم المشروع (الافتراضي: example-job-interactive):
الحزمة المصدر (الافتراضي: interactive.job.example):
مهمة >: init
احصل على مزيد من المساعدة بشأن مشروعك: https://docs.gradle.org/7.5.1/samples/sample_building_scala_applications_multi_project.html
بناء بنجاح في الثلاثينيات
2 مهام قابلة للتنفيذ: 2 منفذة الآن علينا إضافة مستودع Ilum والتبعيات الضرورية إلى build.gradle ملف. في هذا البرنامج التعليمي ، سنستخدم Scala 2.12.
التبعيات {
التنفيذ 'org.scala-lang:scala-library:2.12.16'
التنفيذ 'cloud.ilum:ilum-job-api:5.0.1'
compileOnly 'org.apache.spark:spark-sql_2.12:3.1.2'
} الآن يمكننا إنشاء فئة Scala التي توسع وظيفة Ilum والتي تحسب PI:
الحزمة interactive.job.example
استيراد cloud.ilum.job.Job
استيراد org.apache.spark.sql.SparkSession
استيراد scala.math.random
class InteractiveJobExample يمتد الوظيفة {
تجاوز def run(sparkSession: SparkSession, config: Map[String, Any]): Option[String] = {
val slices = config.getOrElse("slices", "2").toString.toInt
val n = math.min (100000 لتر * شرائح ، Int.MaxValue) .toInt
عدد val = sparkSession.sparkContext.parallelize (1 حتى n ، شرائح).map { i = >
فال س = عشوائي * 2 - 1
val y = عشوائي * 2 - 1
إذا كان (x * x + y * y <= 1) 1 آخر 0
}.تقليل (_ + _)
بعض (s"Pi هو تقريبا ${4.0 * count / (n - 1)}")
}
} إذا أنشأ Gradle بعض الفئات الرئيسية أو الاختبارية ، فما عليك سوى إزالتها من المشروع وإنشاء إنشاء.
$ gradle بناء يجب أن يكون ملف jar الذي تم إنشاؤه في ' ./interactive-job-example/app/build/libs/app.jar "، يمكننا بعد ذلك العودة إلى إيلوم. بمجرد تشغيل جميع الجراب ، يرجى إنشاء منفذ للأمام ل ilum-ui:
المنفذ إلى الأمام SVC / ILUM-UI 9777: 9777 افتح واجهة مستخدم Ilum في متصفحك وأنشئ مجموعة جديدة:
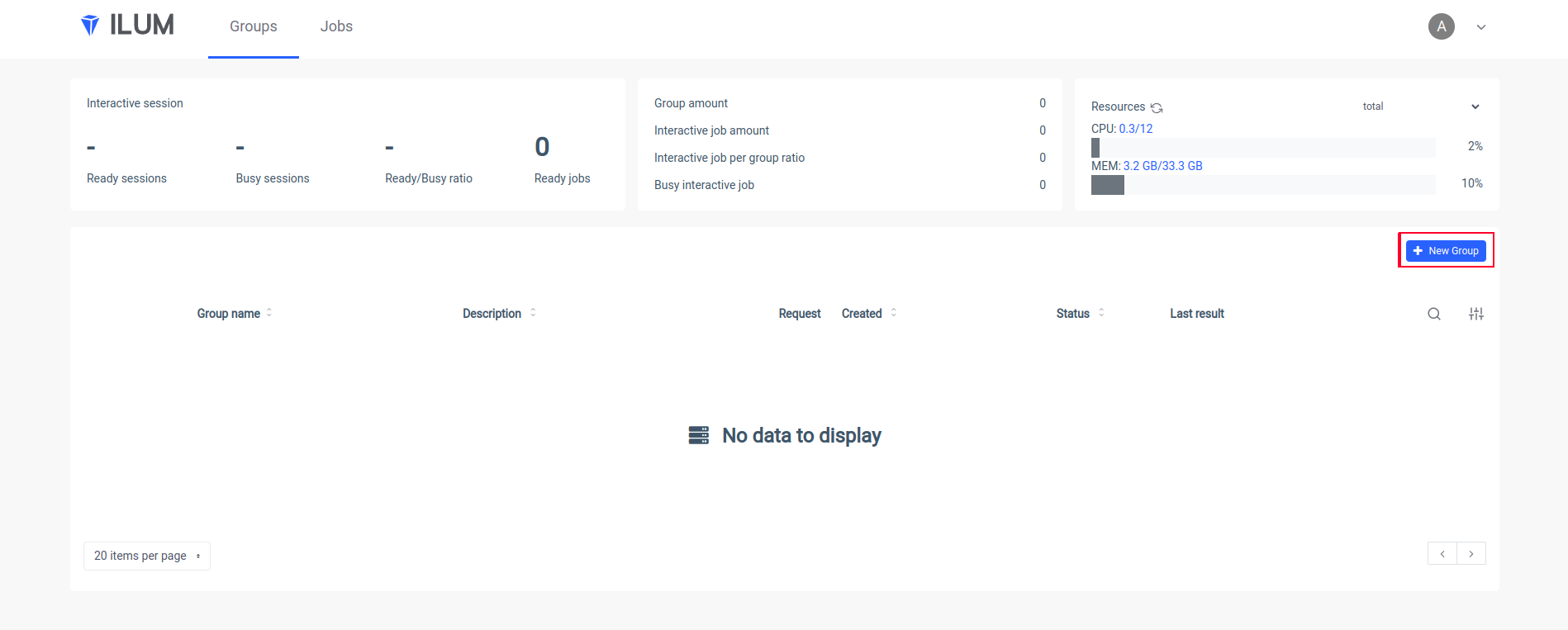
ضع اسما لمجموعة ، واختر مجموعة أو أنشئها ، وقم بتحميل ملف jar الخاص بك وقم بتطبيق التغييرات:
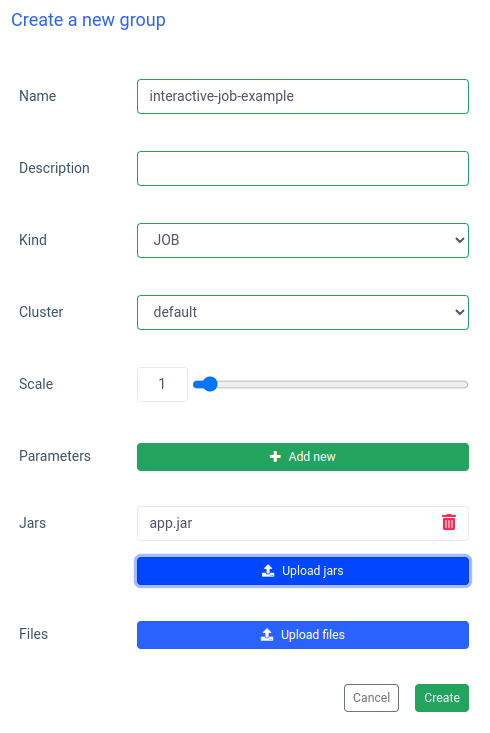
سيقوم Ilum بإنشاء جراب برنامج تشغيل Spark ويمكنك التحكم في عدد كبسولات تنفيذ الشرارة عن طريق تحجيمها. بعد أن تصبح حاوية الشرارة جاهزة ، دعنا ننفذ المهام:
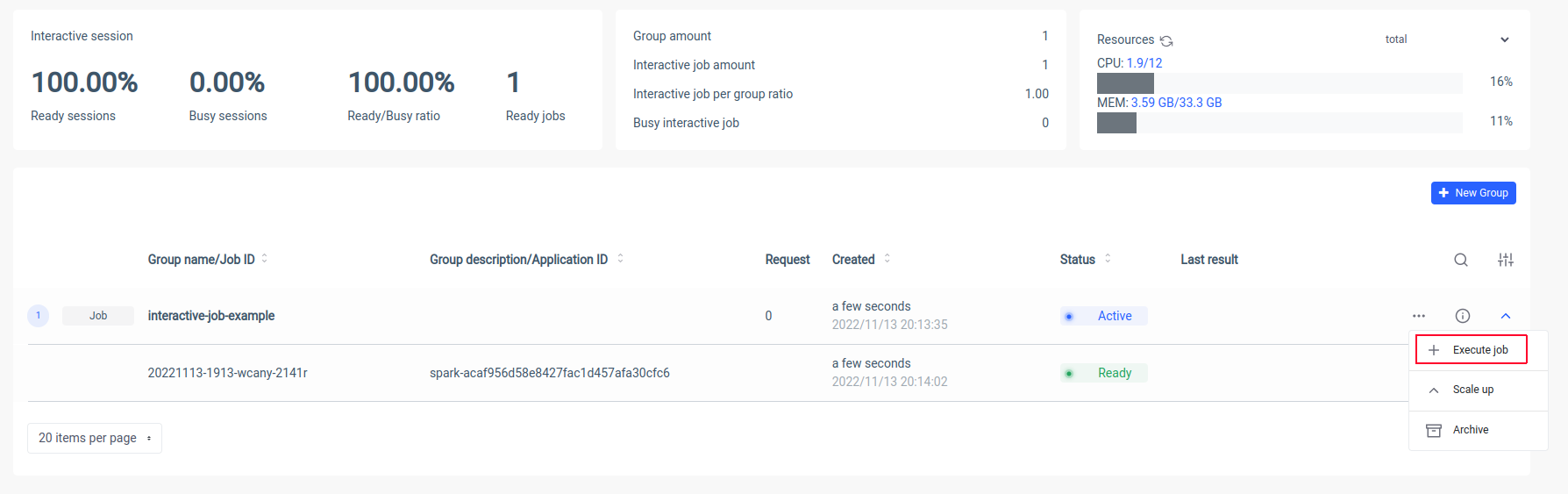
الآن علينا أن نضع الاسم الكنسي لفئة Scala الخاصة بنا
interactive.job.example.InteractiveJobExample وحدد معلمة الشرائح بتنسيق JSON:
{
"config": {
"شرائح": "10"
}
} يجب أن ترى النتيجة مباشرة بعد بدء العمل
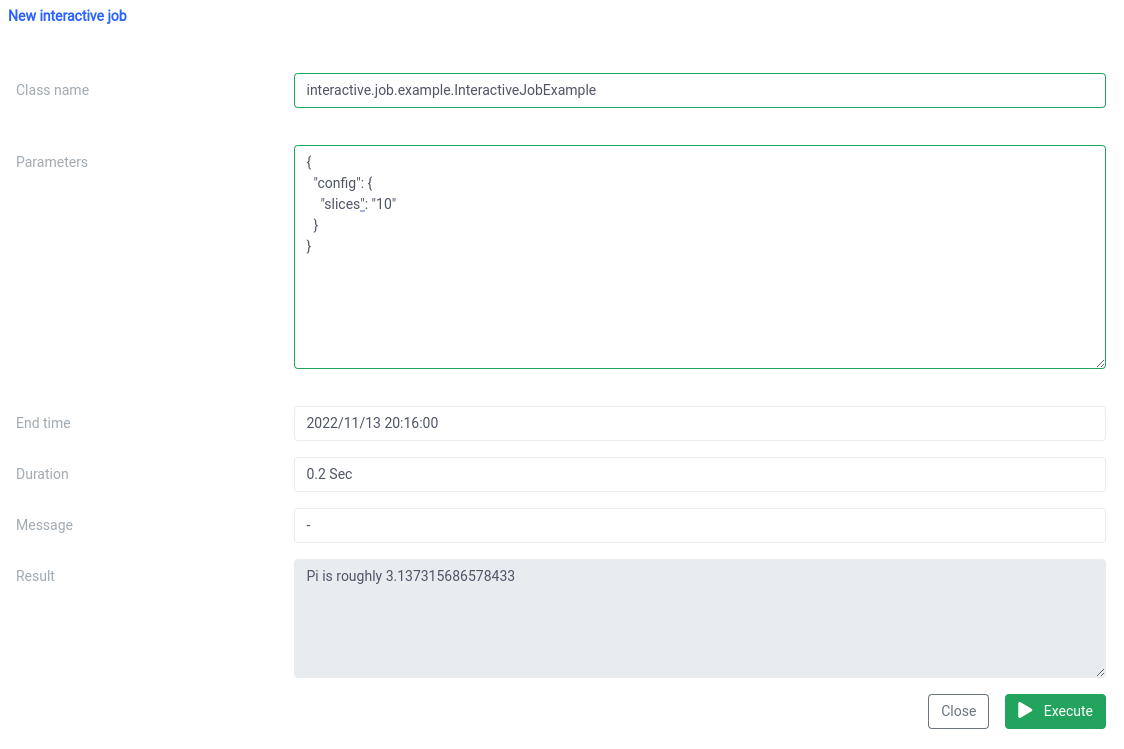
يمكنك تغيير المعلمات وإعادة تشغيل وظيفة وستحدث حساباتك على الفور.
مقارنة تفاعلية ووظيفة واحدة
في إيلوم يمكنك أيضا تشغيل وظيفة واحدة. الاختلاف الأكثر أهمية مقارنة بالوضع التفاعلي هو أنك لست مضطرا إلى تنفيذ واجهة برمجة تطبيقات الوظيفة. يمكننا استخدام جرة SparkPi من أمثلة Spark:
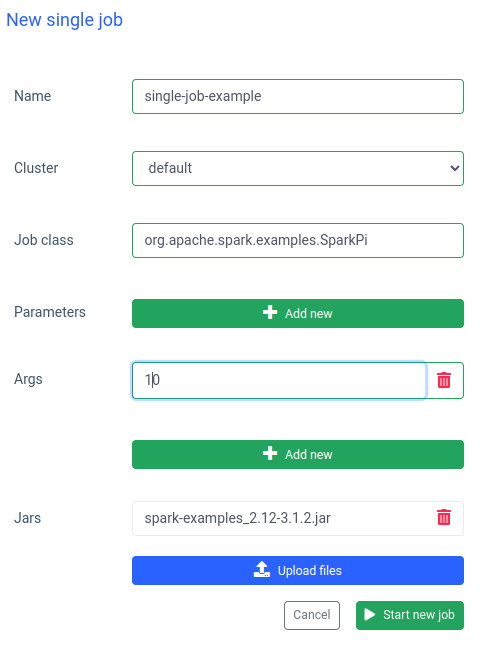
يعد تشغيل وظيفة مثل هذه سريعا أيضا ، ولكن الوظائف التفاعلية أسرع 20 مرة (4 ثوان مقابل 200 مللي ثانية) . إذا كنت ترغب في بدء وظيفة مماثلة بمعلمات أخرى ، فسيتعين عليك إعداد وظيفة جديدة وتحميل الجرة مرة أخرى.
مقارنة بين Ilum و Apache Spark العادي
لقد قمت بإعداد Apache Spark محليا باستخدام ملف بيتنامي / سبارك صورة عامل الإرساء. إذا كنت ترغب أيضا في تشغيل Spark على جهازك ، فيمكنك استخدام docker-compose:
$ curl -LO https://raw.githubusercontent.com/bitnami/containers/main/bitnami/spark/docker-compose.yml
$ عامل الإرساء - تأليف بمجرد تشغيل Spark ، يجب أن تكون قادرا على الانتقال إلى localhost: 8080 والاطلاع على واجهة مستخدم المسؤول. نحتاج إلى الحصول على عنوان URL الخاص ب Spark من المتصفح:

بعد ذلك ، يتعين علينا فتح حاوية Spark في الوضع التفاعلي باستخدام
$ docker exec -it <containerid> -- باش 
والآن داخل الحاوية ، يمكننا إرسال وظيفة sparkPi. في هذه الحالة ، ستستخدم SparkiPi من جرة الأمثلة ، وكمعلمة رئيسية ، ضع عنوان URL من المتصفح:
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi\
- سيد spark://78c84485d233:7077 \
/opt/bitnami/spark/examples/jars/spark-examples_2.12-3.3.0.jar\
10 ملخص
كما ترى في المثال أعلاه ، يمكنك تجنب التكوين المعقد وتثبيت عميل Spark الخاص بك باستخدام Ilum. يتولى Ilum العمل ويوفر لك واجهة بسيطة ومريحة. علاوة على ذلك ، يسمح لك بالتغلب على قيود Apache Spark ، والتي قد تستغرق وقتا طويلا جدا للتهيئة. إذا كان عليك القيام بالعديد من عمليات تنفيذ المهام بمنطق مماثل ولكن بمعلمات مختلفة وترغب في إجراء العمليات الحسابية على الفور ، فيجب عليك بالتأكيد استخدام وضع الوظيفة التفاعلي.

أوجه التشابه مع أباتشي ليفي
Ilum هي أداة سحابية أصلية لإدارة عمليات نشر Apache Spark على Kubernetes. إنه مشابه ل Apache Livy من حيث الوظائف - يمكنه التحكم في Spark Session عبر REST API وبناء تفاعل في الوقت الفعلي مع Spark Cluster. ومع ذلك ، تم تصميم Ilum خصيصا للبيئات السحابية الأصلية الحديثة.
استخدمنا Apache Livy في الماضي ، لكننا وصلنا إلى النقطة التي لم تكن فيها Livy مناسبة للبيئات الحديثة. ليفي عفا عليها الزمن مقارنة ب Ilum. في عام 2018، بدأنا في نقل جميع بيئاتنا إلى Kubernetes، وكان علينا إيجاد طريقة لنشر Apache Spark ومراقبته وصيانته على Kubernetes. كانت هذه مناسبة مثالية لبناء إيلوم.