نشر خدمة PySpark المصغرة على Kubernetes: إحداث ثورة في بحيرات البيانات باستخدام Ilum.

تحياتي عشاق Ilum ومحبي Python! يسعدنا أن نكشف النقاب عن ميزة جديدة منتظرة بفارغ الصبر تم إعدادها لتمكين رحلة علم البيانات الخاصة بك - دعم Python الكامل في Ilum. بالنسبة لأولئك الذين يعملون في عالم البيانات ، لطالما كان Python و Apache Spark ثنائيا مبدعا ، حيث يتعاملان بسلاسة مع كميات هائلة من البيانات والحسابات المعقدة. والآن ، مع أحدث ترقية ل Ilum ، يمكنك تسخير قوة Python داخل بيئة بحيرة البيانات المفضلة لديك.
منشور المدونة هذا هو جولتك المصحوبة بمرشدين لاستكشاف هذه الميزة. سنبدأ الأمور بمهمة Apache Spark بسيطة مكتوبة بلغة Python ، وتشغيلها على Ilum ، ثم نتعمق أكثر. سنقوم بتحويل التعليمات البرمجية الأولية لدعم الوضع التفاعلي ، مما يوفر لك وصولا مباشرا إلى وظيفة Spark عبر واجهة برمجة تطبيقات Ilum. بنهاية هذه الرحلة ، سيكون لديك خدمة مصغرة تستند إلى Python تستجيب لمكالمات واجهة برمجة التطبيقات ، وكلها تعمل بسلاسة على Ilum.
لذا ، هل أنت مستعد لتحسين لعبة البيانات الخاصة بك باستخدام Python و Ilum؟ هيا بنا نبدأ.
جميع الأمثلة متوفرة على موقعنا مستودع GitHub .
الخطوة 1: كتابة وظيفة Apache Spark بسيطة في Python.
قبل أن نبدأ رحلتنا مع Python مع Ilum ، نحتاج إلى التأكد من أن بيئتنا مجهزة جيدا. لتشغيل وظيفة Spark ، تحتاج إلى تثبيت Ilum و PySpark. يمكنك استخدام pip، مثبت حزمة Python، لإعداد PySpark. تأكد من أنك تستخدم Python > = 3.9.
تثبيت PIP Pyspark لإعداد Ilum والوصول إليه ، يرجى اتباع الإرشادات المقدمة هنا .
1.1 مثال SparkPi.
الآن ، دعنا نتعمق في كتابة وظيفة Spark الخاصة بنا. سنبدأ بمثال بسيط على SparkPi
استيراد أنظمة
من عشوائي استيراد عشوائي
من استيراد المشغل إضافة
من pyspark.sql استيراد SparkSession
إذا كان __name__ == "__main__":
شرارة = SparkSession \
.بان\
.appName("PythonPi") \
.getOrCreate ()
الأقسام = int (sys.argv [1]) إذا كان len (sys.argv) > 1 آخر 2
ن = 100000 * أقسام
def f(_: int) -> تعويم:
x = عشوائي () * 2 - 1
y = عشوائي () * 2 - 1
إرجاع 1 إذا كان x ** 2 + y ** 2 <= 1 آخر 0
count = spark.sparkContext.parallelize (النطاق (1 ، ن + 1) ، الأقسام) .map (f) .reduce (إضافة)
print("Pi هو تقريبا٪ f"٪ (4.0 * عدد / n))
spark.stop() احفظ هذا البرنامج النصي ك ilum_python_simple.py
مع استعداد وظيفة Spark الخاصة بنا ، حان الوقت لتشغيلها على Ilum. يوفر Ilum القدرة على إرسال الوظائف باستخدام واجهة مستخدم Ilum أو من خلال واجهة برمجة تطبيقات REST.
لنبدأ بواجهة المستخدم باستخدام ميزة وظيفة واحدة.
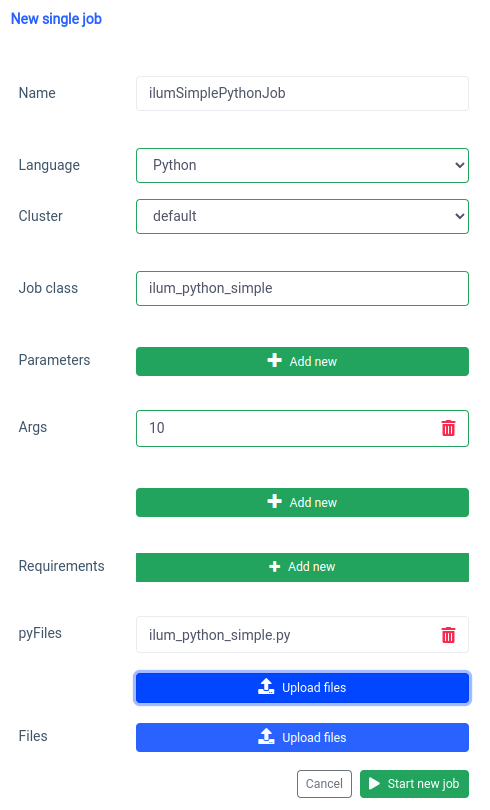
يمكننا تحقيق نفس الشيء مع واجهة برمجة التطبيقات ، ولكن أولا ، نحتاج إلى عرض ilum-core API مع إعادة توجيه المنفذ.
المنفذ إلى الأمام SVC / ILUM الأساسي 9888: 9888 باستخدام المنفذ المكشوف ، يمكننا إجراء استدعاء واجهة برمجة التطبيقات.
curl -X POST 'المضيف المحلي: 9888 / API / v1 / job / submit' \
--form 'name="ilumSimplePythonJob"' \
--form 'clusterName="default"' \
--نموذج 'jobClass="ilum_python_simple"' \
--form 'args="10"' \
--form 'pyFiles=@"/path/to/ilum_python_simple.py"' \
--form 'language="PYTHON"' استدعاء واجهة برمجة التطبيقات
نتيجة لذلك ، سنتلقى معرف الوظيفة التي تم إنشاؤها.
{"jobId":"20230724-1154-m78f3gmlo5j"} نتيجة
للتحقق من سجلات الوظيفة ، يمكننا إجراء استدعاء API إلى
الضفيرة المضيف المحلي:9888/api/v1/job/20230724-1154-m78f3gmlo5j/logs استدعاء واجهة برمجة التطبيقات
وهذا كل شيء! لقد كتبت وقمت بتشغيل وظيفة Python Spark بسيطة على Ilum. دعونا نلقي نظرة على مثال أكثر تقدما يحتاج إلى مكتبات Python إضافية.
1.2 مثال على وظيفة مع numpy.
في هذا القسم ، سنستعرض مثالا عمليا لوظيفة Spark مكتوبة بلغة Python. تتضمن هذه الوظيفة قراءة مجموعة بيانات ومعالجتها وتدريب نموذج التعلم الآلي عليها وحفظ التنبؤات. سنستخدم Tel-churn.csv ، والتي يمكنك العثور عليها في موقعنا مستودع GitHub . لتسهيل الأمور ، قمنا بتحميل هذا الملف إلى حاوية تسمى ilum-files في المثيل المدمج ل MinIO ، والذي يمكن الوصول إليه تلقائيا من مثيل Ilum. هذا يعني أنه لا داعي للقلق بشأن تكوين أي وصولات لهذا المثال - لقد قام Ilum بتغطيته. ومع ذلك، إذا كنت ترغب في أي وقت في جلب البيانات من حاوية مختلفة أو استخدام Amazon S3 في مشاريعك الخاصة، فستحتاج إلى تكوين عمليات الوصول وفقا لذلك.
الآن بعد أن جهزنا بياناتنا ، لنبدأ في كتابة وظيفة Spark الخاصة بنا في Python. فيما يلي مثال التعليمات البرمجية الكاملة:
من pyspark.sql استيراد SparkSession
من pyspark.ml استيراد خط أنابيب
من pyspark.ml.feature استيراد StringIndexer ، VectorAssembler
من pyspark.ml.classification استيراد LogisticRegression
إذا كان __name__ == "__main__":
شرارة = SparkSession \
.بان\
.appName("IlumAdvancedPythonExample") \
.getOrCreate ()
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True)
categoricalColumns = ['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService',
"OnlineSecurity" ، "OnlineBackup" ، "DeviceProtection" ، "TechSupport" ، "StreamingTV" ،
"StreamingMovies" ، "Contract" ، "PaperlessBilling" ، "PaymentMethod"]
المراحل = []
ل categoricalCol في categoricalColumns:
stringIndexer = StringIndexer (inputCol = categoricalCol ، outputCol = categoricalCol + "Index")
مراحل += [stringIndexer]
label_stringIdx = StringIndexer (inputCol = "Mourn" ، outputCol = "التسمية")
المراحل += [label_stringIdx]
numericCols = ['SeniorCitizen', 'longure', 'MonthlyCharges']
assemblerInputs = [c + "فهرس" ل c في categoricalColumns] + numericCols
مجمع = VectorAssembler (inputCols = assemblerInputs ، outputCol = "الميزات")
المراحل += [المجمع]
خط أنابيب = خط أنابيب (مراحل = مراحل)
pipelineModel = pipeline.fit (df)
df = pipelineModel.transform(df)
القطار ، الاختبار = df.randomSplit ([0.7 ، 0.3] ، البذور = 42)
lr = الانحدار اللوجستي (featuresCol = "الميزات" ، labelCol = "label" ، maxIter = 10)
lrModel = lr.fit (قطار)
التنبؤات = lrModel.transform (اختبار)
predictions.select("معرف العميل", "التسمية", "التنبؤ").show(5)
predictions.select("customerID", "label", "prediction").write.option("header", "true") \
.csv('s3a://ilum-files/predictions')
spark.stop() دعنا نتعمق في الكود:
من pyspark.sql استيراد SparkSession
من pyspark.ml استيراد خط أنابيب
من pyspark.ml.feature استيراد StringIndexer ، VectorAssembler
من pyspark.ml.classification استيراد LogisticRegression هنا، نقوم باستيراد وحدات PySpark النمطية الضرورية لإنشاء جلسة Spark، وإنشاء مسار التعلم الآلي، والمعالجة المسبقة للبيانات، وتشغيل نموذج الانحدار اللوجستي.
شرارة = SparkSession \
.بان\
.appName("IlumAdvancedPythonExample") \
.getOrCreate () نقوم بتهيئة جلسة سبارك ، وهي نقطة الدخول إلى أي وظيفة في Spark. هذا هو المكان الذي قمنا فيه بتعيين اسم التطبيق الذي سيظهر على واجهة مستخدم الويب Spark.
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True) نحن نقرأ ملف CSV مخزن على دلو minio. ال header=صحيح يخبر الخيار Spark باستخدام الصف الأول من ملف CSV كرؤوس، بينما inferSchema=صحيح يجعل Spark يحدد تلقائيا نوع البيانات لكل عمود.
categoricalColumns = ['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService',
"OnlineSecurity" ، "OnlineBackup" ، "DeviceProtection" ، "TechSupport" ، "StreamingTV" ،
"StreamingMovies" ، "Contract" ، "PaperlessBilling" ، "PaymentMethod"] نحدد الأعمدة الفئوية في بياناتنا. سيتم تحويلها لاحقا باستخدام StringIndexer.
المراحل = []
ل categoricalCol في categoricalColumns:
stringIndexer = StringIndexer (inputCol = categoricalCol ، outputCol = categoricalCol + "Index")
مراحل += [stringIndexer] هنا ، نقوم بالتكرار على قائمة الأعمدة الفئوية الخاصة بنا وإنشاء StringIndexer لكل منها. يقوم StringIndexers بتشفير أعمدة السلسلة الفئوية في عمود من الفهارس. سيتم تسمية عمود الفهرس المحول باسم العمود الأصلي الملحق ب "الفهرس".
numericCols = ['SeniorCitizen', 'longure', 'MonthlyCharges']
assemblerInputs = [c + "فهرس" ل c في categoricalColumns] + numericCols
مجمع = VectorAssembler (inputCols = assemblerInputs ، outputCol = "الميزات")
المراحل += [المجمع] نقوم هنا بإعداد البيانات لنموذج التعلم الآلي الخاص بنا. نقوم بإنشاء VectorAssembler الذي سيأخذ جميع أعمدة الميزات الخاصة بنا (الفئوية والعددية) ويجمعها في عمود متجه واحد. هذا مطلب لمعظم خوارزميات التعلم الآلي في Spark.
القطار ، الاختبار = df.randomSplit ([0.7 ، 0.3] ، البذور = 42) قمنا بتقسيم بياناتنا إلى مجموعة تدريب ومجموعة اختبار ، مع 70٪ من البيانات للتدريب و 30٪ المتبقية للاختبار.
lr = الانحدار اللوجستي (featuresCol = "الميزات" ، labelCol = "label" ، maxIter = 10)
lrModel = lr.fit (قطار) نقوم بتدريب نموذج الانحدار اللوجستي على بيانات التدريب الخاصة بنا.
التنبؤات = lrModel.transform (اختبار)
predictions.select("معرف العميل", "التسمية", "التنبؤ").show(5)
predictions.select("customerID", "label", "prediction").write.option("header", "true") \
.csv('s3a://ilum-files/predictions') أخيرا ، نستخدم نموذجنا المدرب لعمل تنبؤات على مجموعة الاختبار الخاصة بنا ، وعرض أول 5 تنبؤات. ثم نكتب هذه التنبؤات مرة أخرى إلى دلو المصغر الخاص بنا.
احفظ هذا البرنامج النصي ك ilum_python_advanced.py
يستخدم pyspark.ml numpy كتبعية لم يتم تثبيتها كافتراضي ، لذلك نحتاج إلى تحديده كمتطلب.
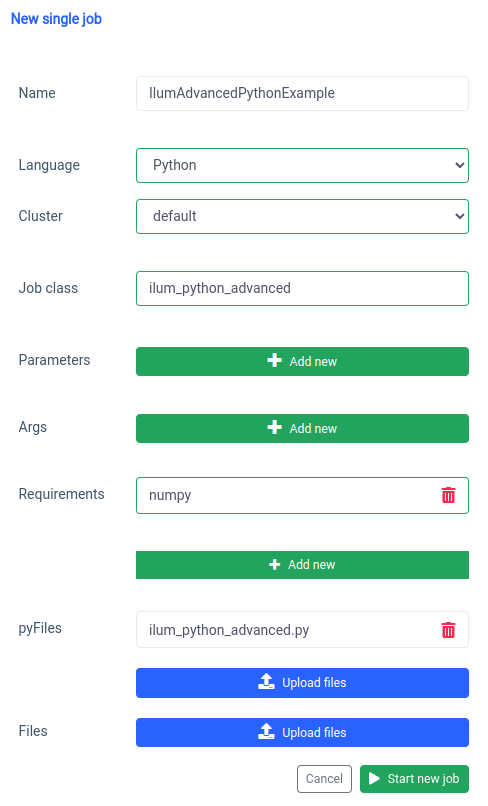
ويمكن القيام بنفس الشيء من خلال واجهة برمجة التطبيقات.
curl -X POST 'المضيف المحلي: 9888 / API / v1 / job / submit' \
--form 'name="IlumAdvancedPythonExample"' \
--form 'clusterName="default"' \
--نموذج 'jobClass="ilum_python_advanced"' \
--form 'pyRequirements="numpy"' \
--form 'pyFiles=@"/path/to/ilum_python_advanced.py"' \
--form 'language="PYTHON"' استدعاء واجهة برمجة التطبيقات
في الأقسام التالية ، سنقوم بتحويل كل من البرامج النصية Python إلى تبادلي شرارة العمل ، مستفيدا كاملا من قدرات Ilum.
الخطوة 2: الانتقال إلى الوضع التفاعلي
الوضع التفاعلي هو ميزة مثيرة تجعل تطوير Spark أكثر ديناميكية ، مما يمنحك القدرة على تشغيل مهام Spark الخاصة بك والتفاعل معها والتحكم فيها في الوقت الفعلي. إنه مصمم لأولئك الذين يسعون إلى مزيد من التحكم المباشر في تطبيقات Spark الخاصة بهم.
فكر في الوضع التفاعلي على أنه إجراء محادثة مباشرة مع وظيفة Spark الخاصة بك. يمكنك تغذية البيانات وطلب التحويلات وجلب النتائج - كل ذلك في الوقت الفعلي. يؤدي ذلك إلى تحسين سرعة وقدرة خط أنابيب معالجة البيانات بشكل كبير ، مما يجعله أكثر قابلية للتكيف والاستجابة للمتطلبات المتغيرة.
الآن بعد أن أصبحنا على دراية بإنشاء وظيفة Spark الأساسية في Python ، دعنا نأخذ الأمور خطوة إلى الأمام من خلال تحويل وظيفتنا إلى وظيفة تفاعلية يمكنها الاستفادة من إمكانات Ilum في الوقت الفعلي.
2.1 مثال SparkPi.
لتوضيح كيفية نقل وظيفتنا إلى الوضع التفاعلي ، سنقوم بتعديل الوضع السابق ilum_python_simple.py خط.
من عشوائي استيراد عشوائي
من استيراد المشغل إضافة
من ilum.api استيراد IlumJob
فئة SparkPiInteractiveExample (IlumJob):
تشغيل def (self ، spark ، config):
الأقسام = int(config.get('sections', '5'))
ن = 100000 * أقسام
def f(_: int) -> تعويم:
x = عشوائي () * 2 - 1
y = عشوائي () * 2 - 1
إرجاع 1 إذا كان x ** 2 + y ** 2 <= 1 آخر 0
count = spark.sparkContext.parallelize (النطاق (1 ، ن + 1) ، الأقسام) .map (f) .reduce (إضافة)
إرجاع "Pi هو تقريبا٪ f"٪ (4.0 * العد / ن) احفظ هذا ك ilum_python_simple_interactive.py
هناك بعض الاختلافات عن SparkPi الأصلي.
1. باقة Ilum
للبدء ، نقوم باستيراد Ilum Job فئة من حزمة ILUM ، والتي تعمل كفئة أساسية لعملنا التفاعلي.
يتم تغليف منطق وظيفة Spark في فئة تمتد Ilum Job ، لا سيما في إطار ركض أسلوب. يمكننا إضافة حزمة ilum مع:
تثبيت النقطة ILUM 2. شرارة وظيفة في فصل دراسي
يتم تغليف منطق وظيفة Spark في فئة تمتد Ilum Job ، لا سيما في إطار ركض أسلوب.
فئة SparkPiInteractiveExample (IlumJob):
تشغيل def (self ، spark ، config):
# منطق الوظيفة هنا يعد التفاف منطق الوظيفة في فصل ضروري لإطار عمل Ilum للتعامل مع الوظيفة ومواردها. هذا أيضا يجعل الوظيفة عديمة الجنسية وقابلة لإعادة الاستخدام.
3. يتم التعامل مع المعلمات بشكل مختلف:
نحن نأخذ جميع الوسيطات من قاموس التكوين
الأقسام = int(config.get('sections', '5')) يسمح هذا التحول بتمرير معلمات أكثر ديناميكية ويتكامل مع معالجة تكوين Ilum.
4. يتم إرجاع النتيجة بدلا من طباعتها:
يتم إرجاع النتيجة من ركض أسلوب.
إرجاع "Pi هو تقريبا٪ f"٪ (4.0 * العد / ن) من خلال إرجاع النتيجة ، يمكن ل Ilum التعامل معها بطريقة أكثر مرونة. على سبيل المثال ، يمكن ل Ilum تسلسل النتيجة وجعلها متاحة عبر استدعاء واجهة برمجة التطبيقات.
5. لا حاجة لإدارة جلسة Spark يدويا
يدير Ilum جلسة Spark لنا. يتم حقنها تلقائيا في ركض ولا نحتاج إلى إيقافه يدويا.
تشغيل def (self ، spark ، config): تسلط هذه التغييرات الضوء على الانتقال من وظيفة Spark المستقلة إلى وظيفة Ilum التفاعلية. الهدف هو تحسين مرونة الوظيفة وقابليتها لإعادة الاستخدام ، مما يجعلها أكثر ملاءمة للحسابات الديناميكية والتفاعلية وأثناء التنقل.
تتم معالجة إضافة وظيفة شرارة تفاعلية باستخدام وظيفة "المجموعة الجديدة".
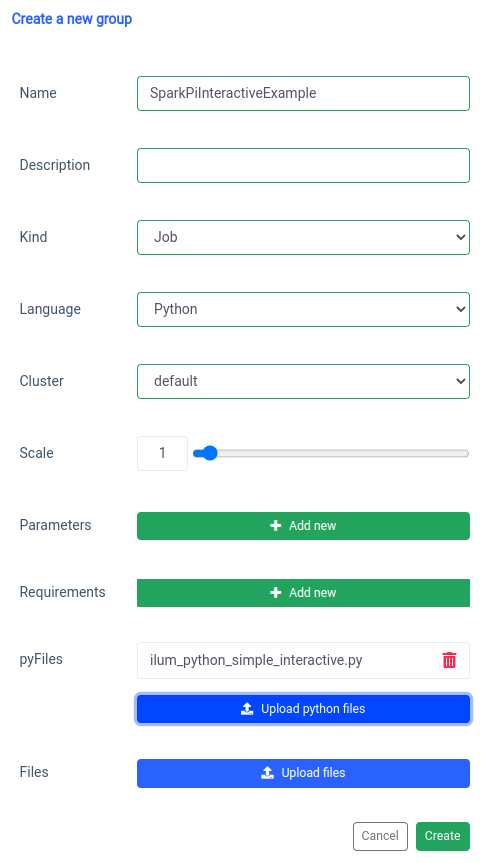
والتنفيذ باستخدام وظيفة الوظيفة التفاعلية على واجهة المستخدم.
يجب تحديد اسم الفئة على أنه pythonFileName.PythonClassImplementingIlumJob
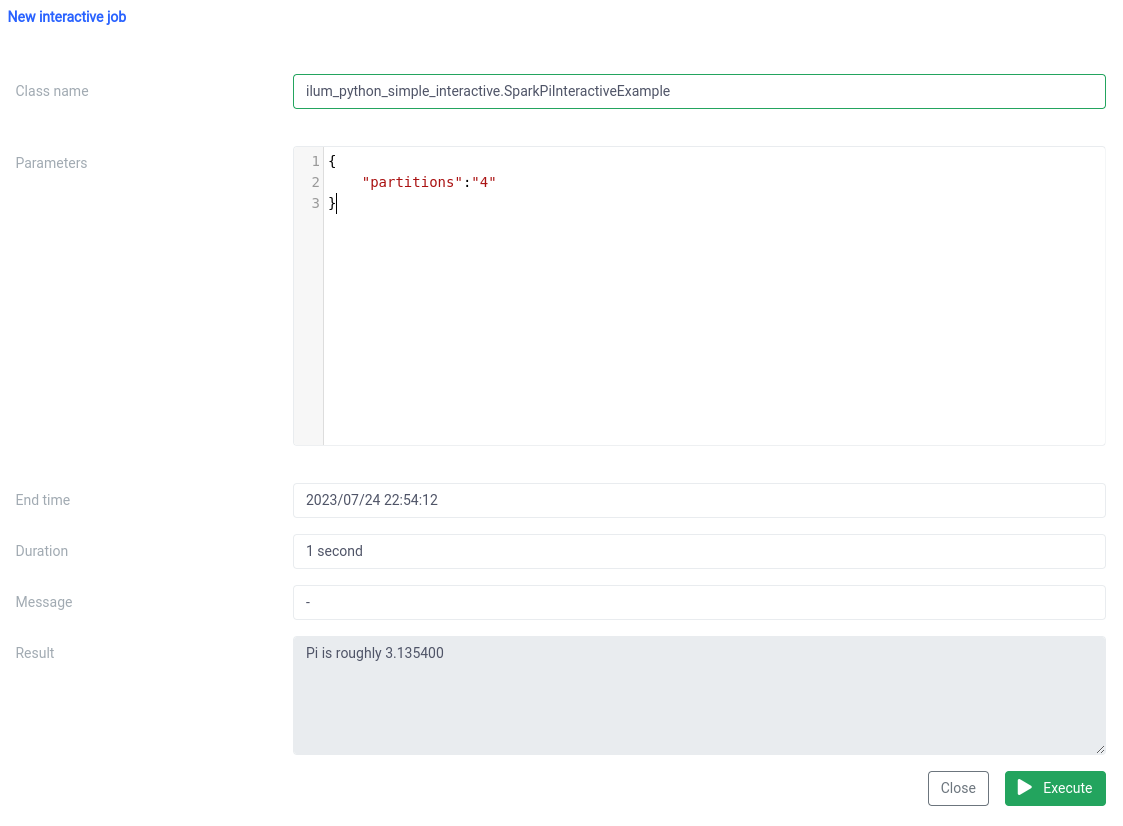
يمكننا تحقيق نفس الشيء مع واجهة برمجة التطبيقات .
1. إنشاء مجموعة
curl -X POST 'المضيف المحلي: 9888 / API / v1 / group' \
--form 'name="SparkPiInteractiveExample"' \
--form 'kind="JOB"' \
--form 'clusterName="default"' \
--form 'pyFiles=@"/path/to/ilum_python_simple_interactive.py"' \
--form 'language="PYTHON"' استدعاء واجهة برمجة التطبيقات
{"groupId":"20230726-1638-mjrw3"} نتيجة
2. تنفيذ الوظيفة
curl -X POST 'المضيف المحلي:9888/api/v1/group/20230726-1638-mjrw3/job/execute' \
-H 'نوع المحتوى: التطبيق / json' \
-d '{ "jobClass":"ilum_python_simple_interactive. SparkPiInteractiveExample", "jobConfig": {"partitions":"10"}, "type":"interactive_job_execute"}' استدعاء واجهة برمجة التطبيقات
{
"jobInstanceId":"20230726-1638-mjrw3-a1srahhu",
"jobId":"20230726-1638-mjrw3-wwt5a",
"groupId":"20230726-1638-mjrw3",
"startTime":1690390323154,
"endTime":1690390325200,
"jobClass":"ilum_python_simple_interactive. SparkPiInteractiveExample",
"jobConfig":{
"الأقسام":"10"
},
"النتيجة":"Pi هو تقريبا 3.149400",
"error":null
} نتيجة
2.2 مثال على وظيفة مع numpy.
دعونا نلقي نظرة على المثال الثاني.
من pyspark.sql استيراد SparkSession
من pyspark.ml استيراد خط أنابيب
من pyspark.ml.feature استيراد StringIndexer ، VectorAssembler
من pyspark.ml.classification استيراد LogisticRegression
من ilum.api استيراد IlumJob
فئة LogisticRegressionJobExample(IlumJob):
def run(self, spark_session: SparkSession, config: dict) -> str:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True,
inferSchema=True)
categoricalColumns = ['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService',
"OnlineSecurity" ، "OnlineBackup" ، "DeviceProtection" ، "TechSupport" ، "StreamingTV" ،
"StreamingMovies" ، "Contract" ، "PaperlessBilling" ، "PaymentMethod"]
المراحل = []
ل categoricalCol في categoricalColumns:
stringIndexer = StringIndexer (inputCol = categoricalCol ، outputCol = categoricalCol + "Index")
مراحل += [stringIndexer]
label_stringIdx = StringIndexer (inputCol = "Mourn" ، outputCol = "التسمية")
المراحل += [label_stringIdx]
numericCols = ['SeniorCitizen', 'longure', 'MonthlyCharges']
assemblerInputs = [c + "فهرس" ل c في categoricalColumns] + numericCols
مجمع = VectorAssembler (inputCols = assemblerInputs ، outputCol = "الميزات")
المراحل += [المجمع]
خط أنابيب = خط أنابيب (مراحل = مراحل)
pipelineModel = pipeline.fit (df)
df = pipelineModel.transform(df)
train, test = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))],
seed=int(config.get('seed', '42')))
lr = الانحدار اللوجستي(featuresCol="الميزات", labelCol="label", maxIter=int(config.get('maxIter', '5')))
lrModel = lr.fit (قطار)
التنبؤات = lrModel.transform (اختبار)
إرجاع '{}'.format(predictions.select("customerID", "label", "prediction").limit(
int(config.get('rowLimit', '5'))).toJSON().collect()) 1. نلف الوظيفة في فصل دراسي ، تماما كما في المثال السابق:
فئة LogisticRegressionJobExample(IlumJob):
def run(self, spark_session: SparkSession, config: dict) -> str:
# منطق الوظيفة هنا مرة أخرى ، يتم تغليف منطق الوظيفة في ركض طريقة تمديد الفئة Ilum Job ، مما يساعد إيلوم على التعامل مع المهمة بكفاءة.
2. يتم الحصول على جميع المعلمات ، بما في ذلك تلك الخاصة بمسار البيانات (مثل مسارات الملفات والمعلمات الفائقة للانحدار اللوجستي) ، من التكوين قاموس:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True, inferSchema=True)
train, test = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))], seed=int(config.get('seed', '42')))
lr = الانحدار اللوجستي(featuresCol="الميزات", labelCol="label", maxIter=int(config.get('maxIter', '5'))) من خلال مركزية جميع المعلمات في مكان واحد ، يوفر Ilum طريقة موحدة ومتسقة لتكوين المهمة وضبطها.
يتم إرجاع نتيجة الوظيفة، بدلا من كتابتها إلى موقع معين، كسلسلة JSON:
إرجاع '{}'.format(predictions.select("customerID", "label", "prediction").limit(int(config.get('rowLimit', '5'))).toJSON().collect()) يسمح ذلك بمعالجة أكثر ديناميكية ومرونة لنتيجة الوظيفة، والتي يمكن بعد ذلك معالجتها بشكل أكبر أو عرضها عبر واجهة برمجة التطبيقات، اعتمادا على احتياجات التطبيق.
يوضح هذا الرمز بشكل مثالي كيف يمكننا دمج وظائف PySpark بسلاسة مع Ilum لتمكين خطوط أنابيب معالجة البيانات التفاعلية المستندة إلى واجهة برمجة التطبيقات. من الأمثلة البسيطة مثل تقريب Pi إلى الحالات الأكثر تعقيدا مثل الانحدار اللوجستي ، فإن وظائف Ilom التفاعلية متعددة الاستخدامات وقابلة للتكيف وفعالة.
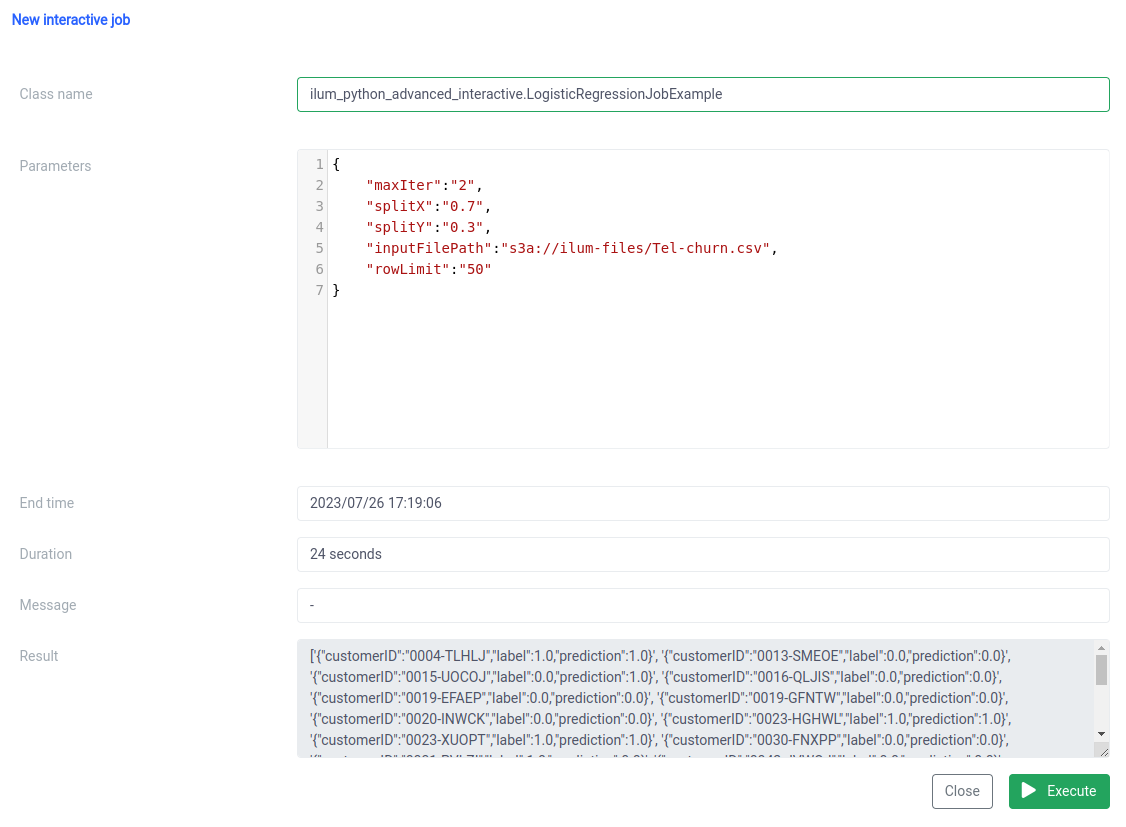
الخطوة 3: اجعل وظيفة Spark الخاصة بك خدمة مصغرة
تجلب الخدمات المصغرة نقلة نوعية من هيكل التطبيق التقليدي المتجانس إلى نهج أكثر نمطية ورشاقة. من خلال تقسيم تطبيق معقد إلى خدمات صغيرة مقترنة بشكل فضفاض ، يصبح من الأسهل إنشاء كل خدمة وصيانتها وتوسيع نطاقها بشكل مستقل بناء على متطلبات محددة. عند تطبيقه على وظيفة Spark الخاصة بنا ، فهذا يعني أنه يمكننا إنشاء خدمة معالجة بيانات قوية يمكن توسيع نطاقها وإدارتها وتحديثها دون التأثير على أجزاء أخرى من حزمة التطبيقات الخاصة بنا.
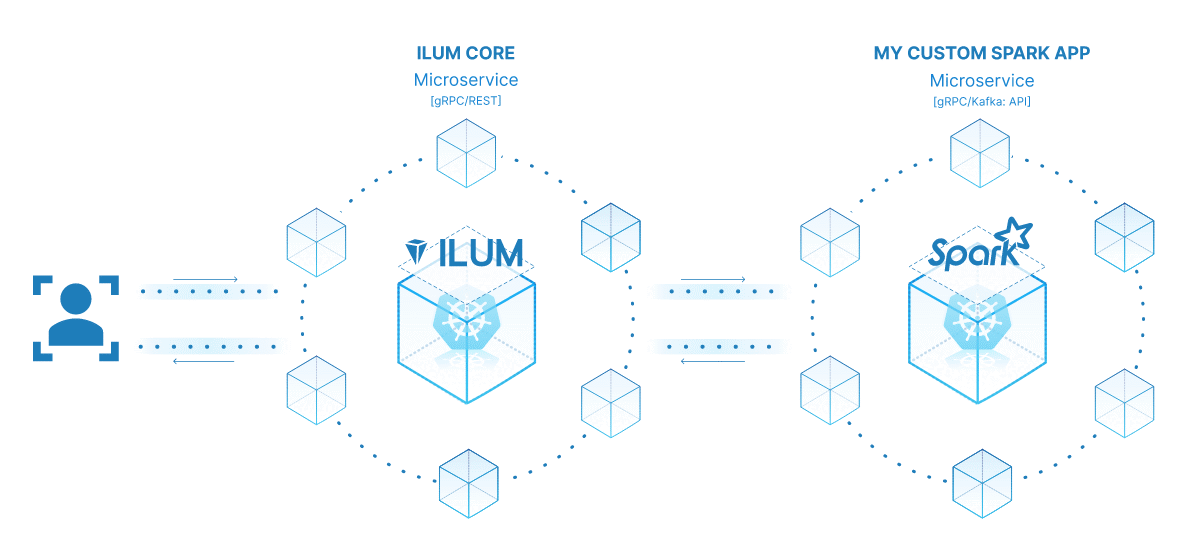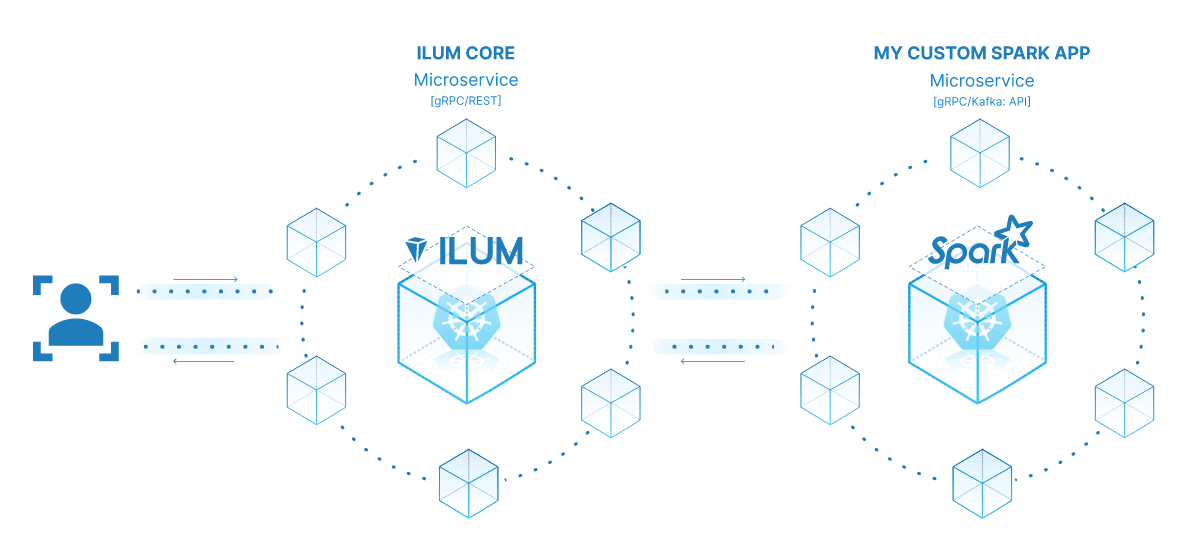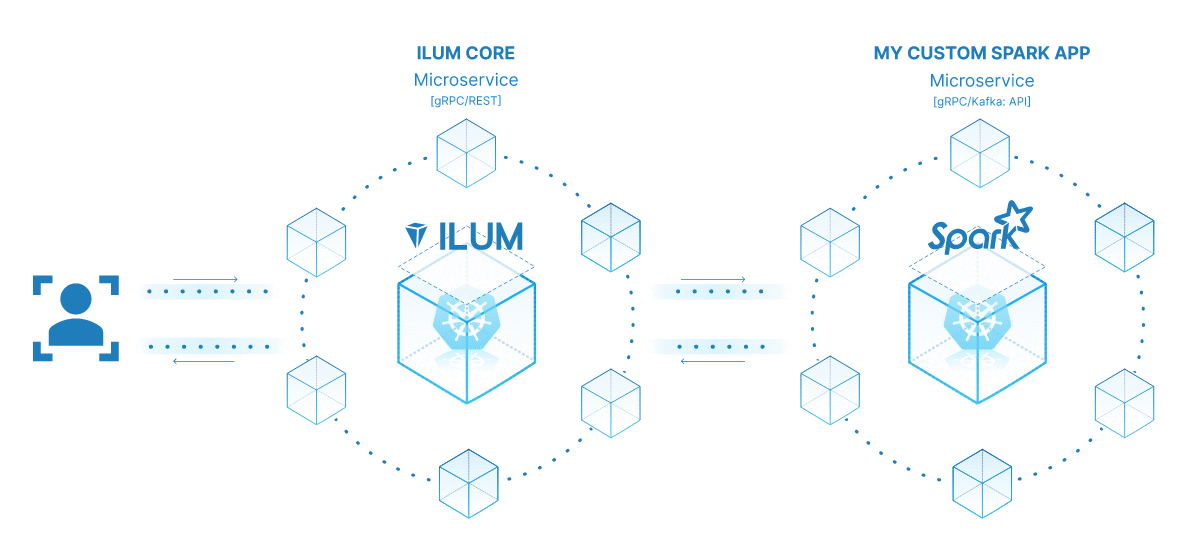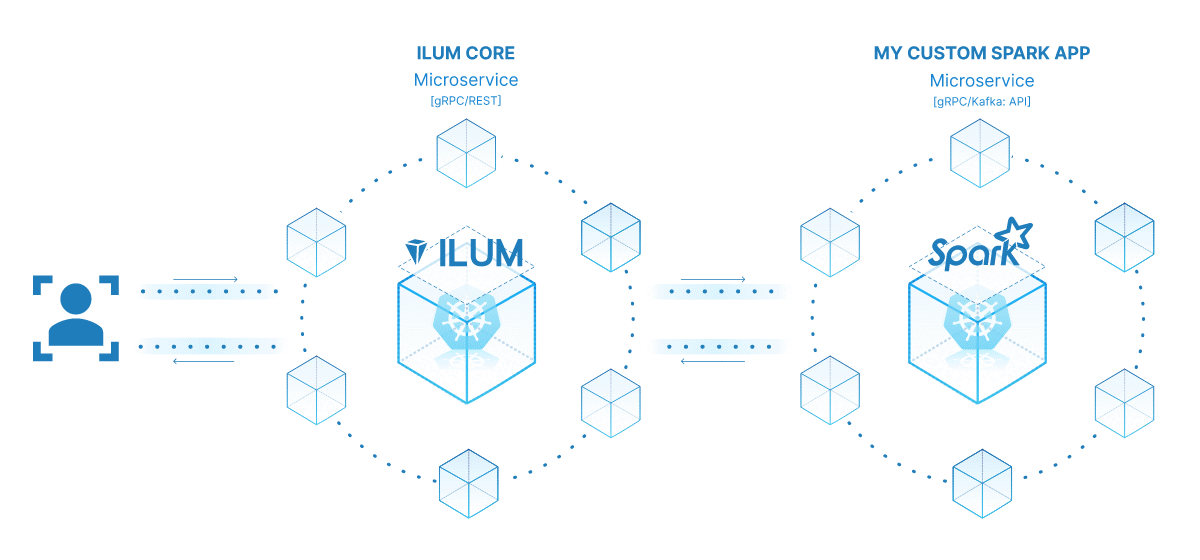
تكمن قوة تحويل وظيفة Spark إلى خدمة مصغرة في تعدد استخداماتها وقابليتها للتوسع وقدرات التفاعل في الوقت الفعلي. الخدمة المصغرة هي مكون قابل للنشر بشكل مستقل لتطبيق يعمل كعملية منفصلة. يتصل بالمكونات الأخرى عبر واجهات برمجة التطبيقات المحددة جيدا ، مما يمنحك حرية تصميم كل خدمة مصغرة وتطويرها ونشرها وتوسيع نطاقها بشكل مستقل.
في سياق Ilum ، يمكن التعامل مع وظيفة Spark التفاعلية كخدمة مصغرة. تعمل طريقة "التشغيل" للوظيفة كنقطة نهاية لواجهة برمجة التطبيقات. في كل مرة تستدعي فيها هذه الطريقة عبر واجهة برمجة تطبيقات Ilum ، فإنك تقدم طلبا إلى هذه الخدمة المصغرة. هذا يفتح إمكانية التفاعلات في الوقت الفعلي مع وظيفة Spark الخاصة بك.
يمكنك تقديم طلبات إلى الخدمة المصغرة الخاصة بك من تطبيقات أو برامج نصية مختلفة ، وجلب البيانات ، ومعالجة النتائج أثناء التنقل. علاوة على ذلك ، فإنه يفتح فرصة لبناء بنى أكثر تعقيدا وموجهة نحو الخدمة حول مسارات معالجة البيانات الخاصة بك.
تتمثل إحدى الميزات الرئيسية لهذا الإعداد في قابلية التوسع. من خلال واجهة مستخدم Ilum أو واجهة برمجة التطبيقات ، يمكنك توسيع نطاق وظيفتك (الخدمة المصغرة) لأعلى أو لأسفل بناء على الحمل أو التعقيد الحسابي. لا داعي للقلق بشأن إدارة الموارد يدويا أو موازنة التحميل. سيقوم موازن التحميل الداخلي في Ilum بتوزيع استدعاءات واجهة برمجة التطبيقات بين مثيلات مهمة Spark الخاصة بك، مما يضمن الاستخدام الفعال للموارد.
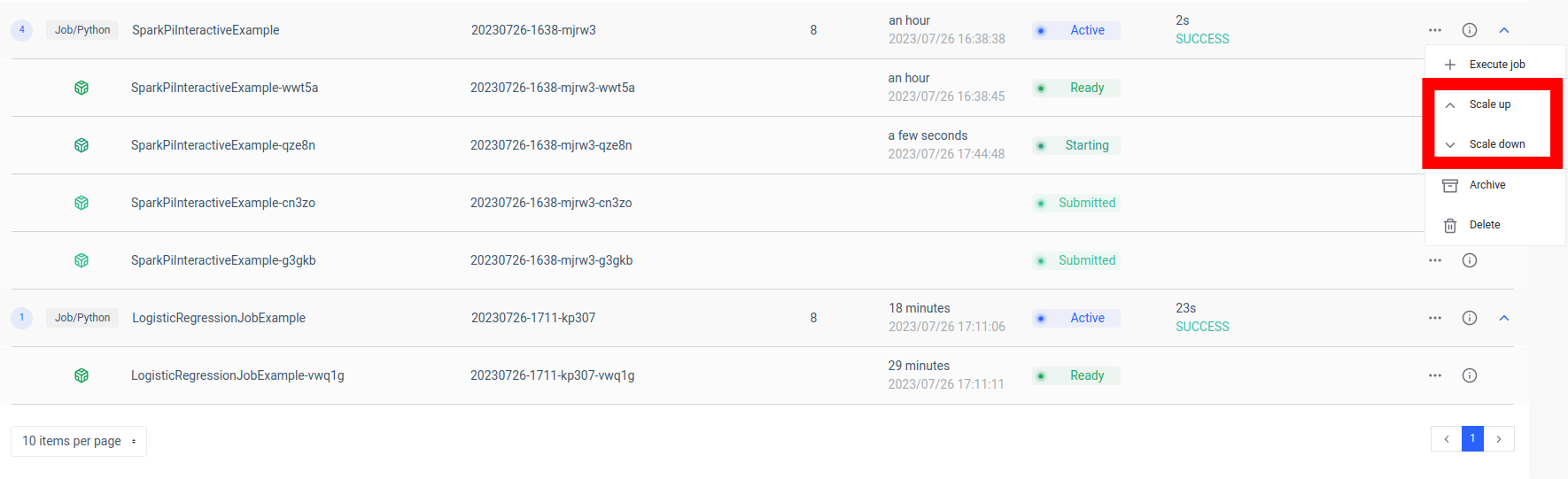
ضع في اعتبارك أن وقت المعالجة الفعلي للمهمة يعتمد على مدى تعقيد وظيفة Spark والموارد المخصصة لها. ومع ذلك ، مع قابلية التوسع التي يوفرها Kubernetes ، يمكنك بسهولة توسيع نطاق مواردك مع نمو متطلبات وظيفتك.
يوفر هذا المزيج من Ilum و Apache Spark والخدمات المصغرة طريقة جديدة ومرنة لمعالجة بياناتك - بكفاءة وقابلية تطوير واستجابة

مغير قواعد اللعبة في بنية الخدمات المصغرة للبيانات
لقد قطعنا شوطا طويلا منذ أن بدأنا هذه الرحلة لتحويل وظيفة Python Apache Spark البسيطة إلى خدمة مصغرة كاملة باستخدام Ilum. لقد رأينا مدى سهولة كتابة وظيفة Spark ، وتكييفها للعمل في الوضع التفاعلي ، وعرضها في النهاية كخدمة مصغرة بمساعدة واجهة برمجة تطبيقات Ilum القوية. على طول الطريق ، استفدنا من قوة Python ، وقدرات Apache Spark ، ومرونة Ilum وقابليتها للتوسع. لم يغير هذا المزيج قدرات معالجة البيانات لدينا فحسب ، بل غير أيضا طريقة تفكيرنا في بنية البيانات.
الرحلة لا تتوقف هنا. مع دعم Python الكامل على Ilum ، يفتح عالم جديد من الاحتمالات لمعالجة البيانات والتحليلات. مع استمرارنا في البناء والتحسين على Ilum ، نحن متحمسون للاحتمالات المستقبلية التي تقدمها Python إلى منصتنا. نعتقد أنه مع Python و Ilum معا ، نحن في بداية إعادة تعريف ما هو ممكن في عالم بنية الخدمات المصغرة للبيانات.
انضم إلينا في هذه الرحلة المثيرة ، ودعنا نشكل مستقبل معالجة البيانات معا!